From Physics based MPC and Bayesian Comfort Models to Deep RL: What still feels right and what I got wrong
—notes from my 2018 MSc thesis, revisited in 2025
Read original 2018 MSc thesis PDF: Humans in the Loop: Model Predictive Control for Thermal Conditioning of Buildings using On-line Learning from Occupant Feedback
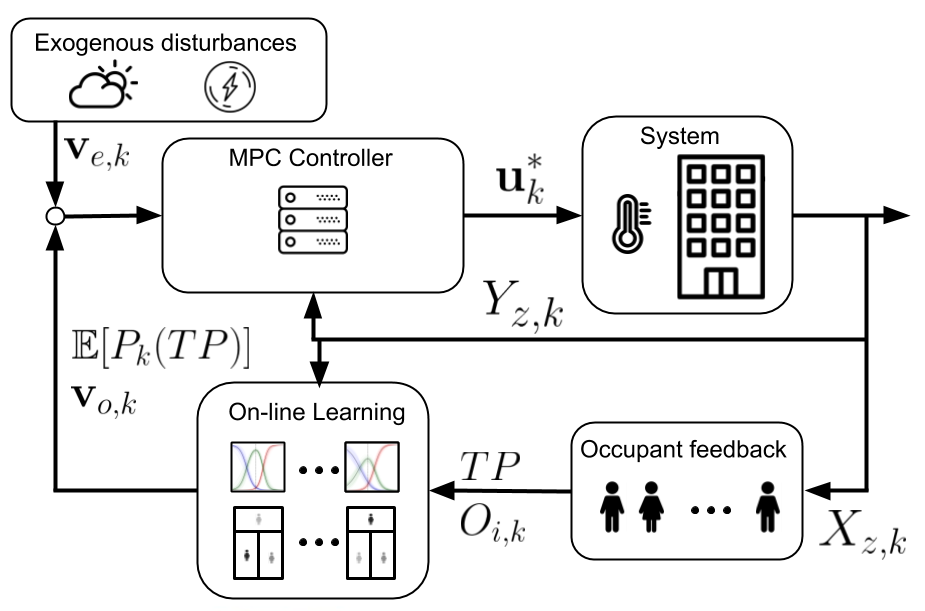
My goal in 2018 for Human-in-the-loop MPC was to optimally balance the cost and benefit provided by an HVAC system by giving the occupany humans real-time feedback they could use and understand. Seven years later, the ML/AI community is buzzing with RLHF with agents. Looking back, here are some insights that I think still matter.
| ✅ What still feels right | ❌ What I got wrong |
|---|---|
| Sample efficiency: Bayesian comfort models learned from ~30 votes per occupant and stayed stable. | Hardware cost: Solving a nonlinear MPC every 15 min or more frequently with edge controllers may not be suitable for larger buildings. |
| Safety by design: Hard constraints were first-class citizens in the MPC, so deployment risk was near-zero. | Representation learning: I assumed linear RC walls and categorical comfort; today’s latent-state models capture far richer dynamics and behaviour and may need different optimization techniques. |
| Human-friendly interaction loop: The ternary UI let occupants express dissatisfaction without fiddling with set-points. | Scalability: My approach optimised one zone; multi-agent coordination across dozens of zones may need graph-based policies or decentralised MPC for tractability. |
| Transparent tuning knobs: Comfort-vs-energy weights had clear physical meaning, easing stakeholder buy-in. | Data scale: I had limited real-world data available for my research, especially sensor continous sensor data which would be crucial for real systems. |
| Hybrid vision: combining physics models that are realiabile and interpretable with learning parameters and prefernences. | Inference latency edge: I didn’t think about operational cost savings from a single forward pass of a deep policy would become compared with repeated optimisation. |
Three key ideas:
1: Keep learning and optimisation decoupled
In my architecture, learning updated probabilistic models of each occupant’s thermal preference and presence via Sequential Monte-Carlo; Model Predictive Control then solved a constrained NLP every 15 minutes.
- The physics-grounded MPC guarantees temperatures and actuator limits—no safety layer bolted on afterwards.
- Tiny data: a handful of occupant votes is enough to tune the model.
2: Rich, explicit feedback beats reward hacking
A single vote—“warmer / no change / cooler”—fed a Bayesian update that slashed comfort-prediction error with just dozens of samples per person.
- Structured labels + informed priors buy orders-of-magnitude sample efficiency.
- In real buildings, every bad experiment costs energy or comfort; you won’t get millions of exploration steps.
3: Reward modelling is the real game
I embedded the expected probability an occupant would ask for a change directly into the cost function—effectively an early inverse-reward-design step.
- Whether you call it RLHF or reward shaping, the core task is translating fuzzy and dynamic human intent into a scalar your optimiser cares about.
- Today’s RL pipelines should dedicate as much engineering to this “outer loss” as to the policy network itself.
